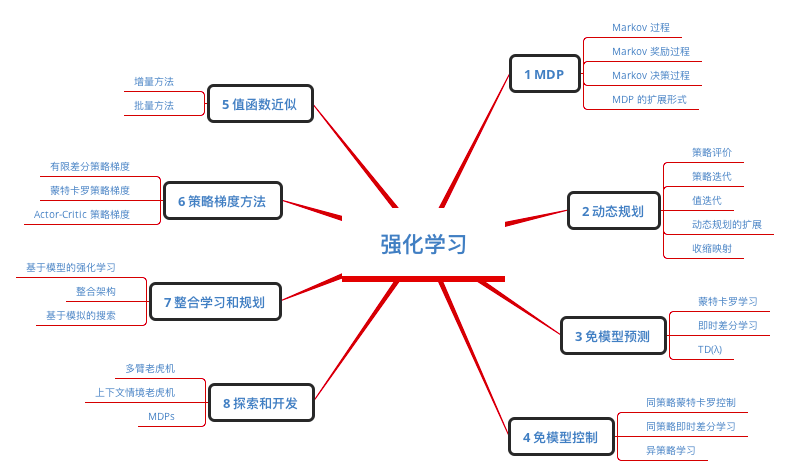
Reinforcement Learning 强化学习
强化学习,现在常常将其看作机器学习领域的一个分支,但如果细细去看,你会发现,强化学习本身也有完整的一条发展的脉络。从动物行为研究和优化控制两个领域独立发展最终经 Bellman 之手汇集抽象为 MDP 问题而完成形式化。之后经很多的科学家的不断扩大,形成了相对完备的体系——常被称为近似动态规划,参看 MIT 教授 Dimitri P. Bertsekas 的 动态规划系列,Dynamic Programming and Optimal Control, Vol. II, 4th Edition: Approximate Dynamic Programming。
强化学习是非常严谨的领域,适合各类人享受/被折磨(数学重起来可以直接 KO 一般的非数学系本科生)。但往往应用起来却非常困难,首先维度灾难的存在使得我们很难高效地求解最优的策略或者计算最优行动值。另外深度学习其中包含的思想——贪婪、动态规划、近似等等都是算法中最为关键的部分,也是这些方法使用得比较极致的地方。因此,才有不少人持续在其上很多年不断地推进研究的深入和一般性。(这里,其实要说一句,国内的强化学习研究并不是特别领先,也要引发我们的思考。另一个有趣的现象是,作为强化学习研究的重镇 Alberta 大学,也就是 Richard Sutton 等计算机科学家领衔的强化学习中心,同样是在加拿大。这种感觉让人想到了 Geoffrey Hinton 在 Toronto 领导的深度学习复兴。个人感觉,国内强化学习研究不能够兴起的原因是研究者本身相对狭窄的视角,与不同学科和思想的连接甚弱,乃至于不敢想象——一句话概括的话,我觉得是勇气和想象力的缺失吧!在现在的研究中看到得更多是很多想法的全方位连接,交叉科学的研究是切切实实地交叉。)
在 Warren B. Powell 的一篇短文中说道,很多来自不同领域的人,都在忙着自己的一亩三分地上耕耘,自得其乐;实际上,大多人做出来同样的工作,因此他提出了 10 条意见。简言之:建议大家从一个全貌看待问题和学科,找到相通联的点,以此出发,找到潜在的连线,最终形成整体的面的认知。
这里结合 David Silver 的强化学习课程给出一个强化学习的概貌: